Designing low-latency AI agents through reranker optimization
Posted on March 25, 2026


Article
At Decagon, low latency is a hard product requirement. When you're speaking with a voice agent, an extra 200–300ms of silence is the difference between a natural conversation and a robotic one, full of awkward pauses and missed cues. Every millisecond we can reclaim translates directly into a better user experience.
We traced a meaningful chunk of our response latency back to a single stage in our RAG pipeline: reranking. Here's what we found, and how we cut reranking latency without replacing the underlying model.
The hidden cost of reranking
RAG is an often-overlooked aspect of agent architecture that can quietly eat into response time. A typical RAG pipeline looks like this: query rewrite → embedding generation → vector retrieval → reranking → final response generation.
Aside from final response generation, reranking typically incurs the largest latency cost, as it must process tens to hundreds of candidate documents before a single token of the final response can be generated, creating a bottleneck for everything that comes after it.
The root cause comes down to how reranking works, and specifically which kind of reranker you're using.
List-wise vs. Point-wise reranking
List-wise rerankers take all candidate documents as input and output a ranked ordering from most to least relevant given the user’s query. The constructed prompts frequently run into the tens of thousands of tokens, which drives up latency due to the quadratic time complexity of transformer attention. The more tokens in the sequence, the disproportionately more expensive the forward pass becomes.
Point-wise rerankers, by contrast, score the relevance between a user query and a single document in isolation. They compute a score for each (query, document) pair independently and then sort the documents in decreasing order of relevance. Because each input is just one query paired with one document, sequence lengths are dramatically shorter and per-call cost becomes far more predictable.
We recently moved from list-wise to point-wise reranking at Decagon and saw a significant reduction in reranking latency as a result.
Efficient batching with attention masking
In practice, however, naively sending tens or hundreds of independent model requests is not always more efficient. The overall reranking step is gated on the slowest individual call, and the overhead of many sequential requests adds up quickly. Instead, we use a technique that manipulates the attention mask to score multiple (query, document) pairs in a single batched forward pass.
Here's how it works: we concatenate multiple (query, document) pairs into a single packed sequence, separated by a delimiter token. We then modify the attention mask so that tokens within each pair attend only to each other, while attention to tokens from other pairs is masked out entirely. This produces a block-diagonal attention pattern (see diagram below) — each document is scored in isolation, but we amortize the overhead of a model call across many pairs at once.
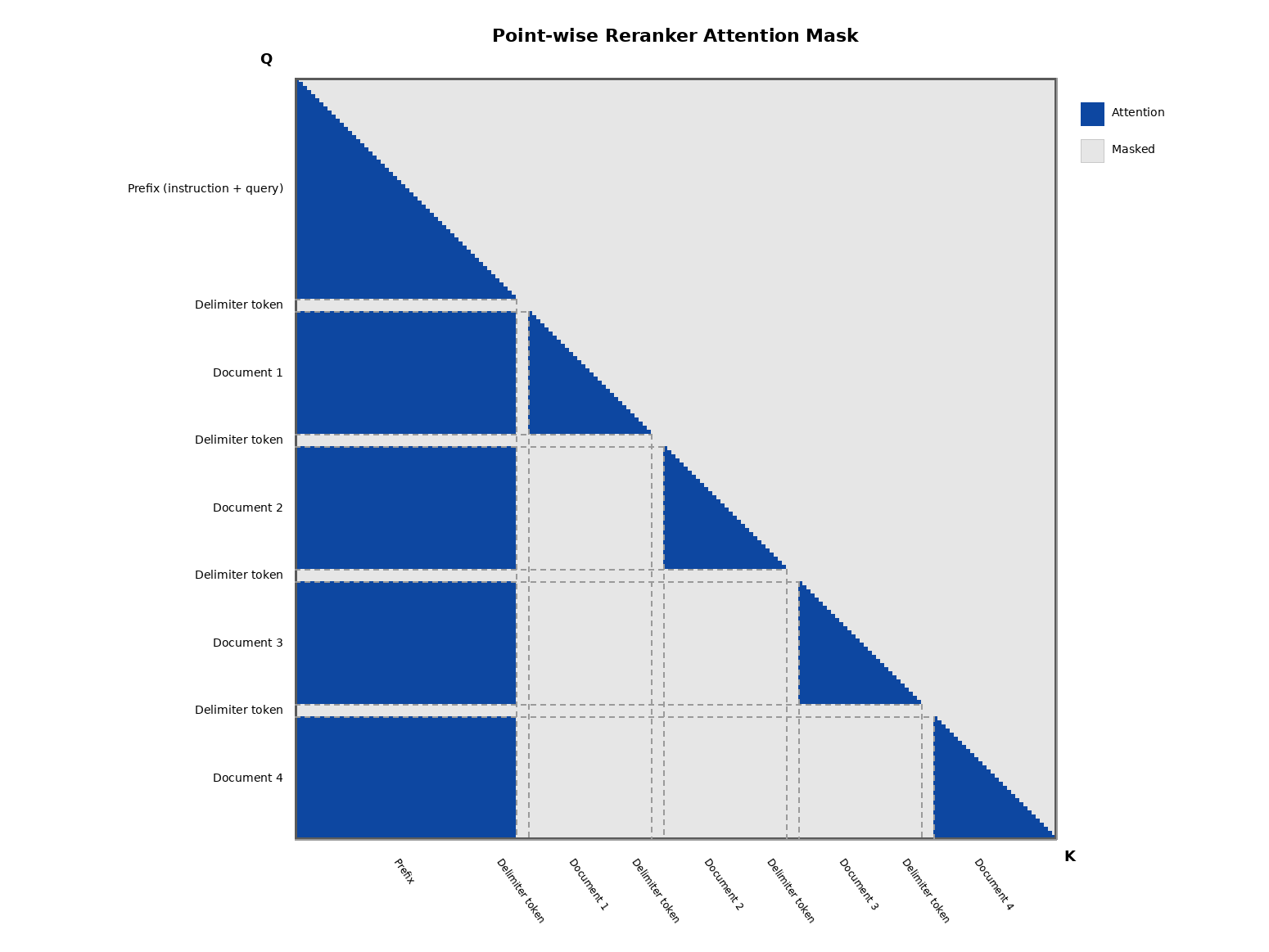
Because relevance scoring isn't an autoregressive process (unlike text generation, it doesn't need to predict tokens one at a time), this packing approach is valid: the pairs don't need to interact with each other to produce correct scores. We get the efficiency of batching without compromising the point-wise scoring semantics.
Finding the optimal batch size
With this packing approach in place, the remaining challenge is straightforward: find the optimize batch size that minimizes end-to-end latency for your system.
Using too few pairs per batch means sending many requests, where the overall step is gated on the slowest call. Using too many causes the packed sequence to grow long enough that per-call processing time starts to climb. We can see in our empirical results below that batch size 2 yields the best latency improvements.
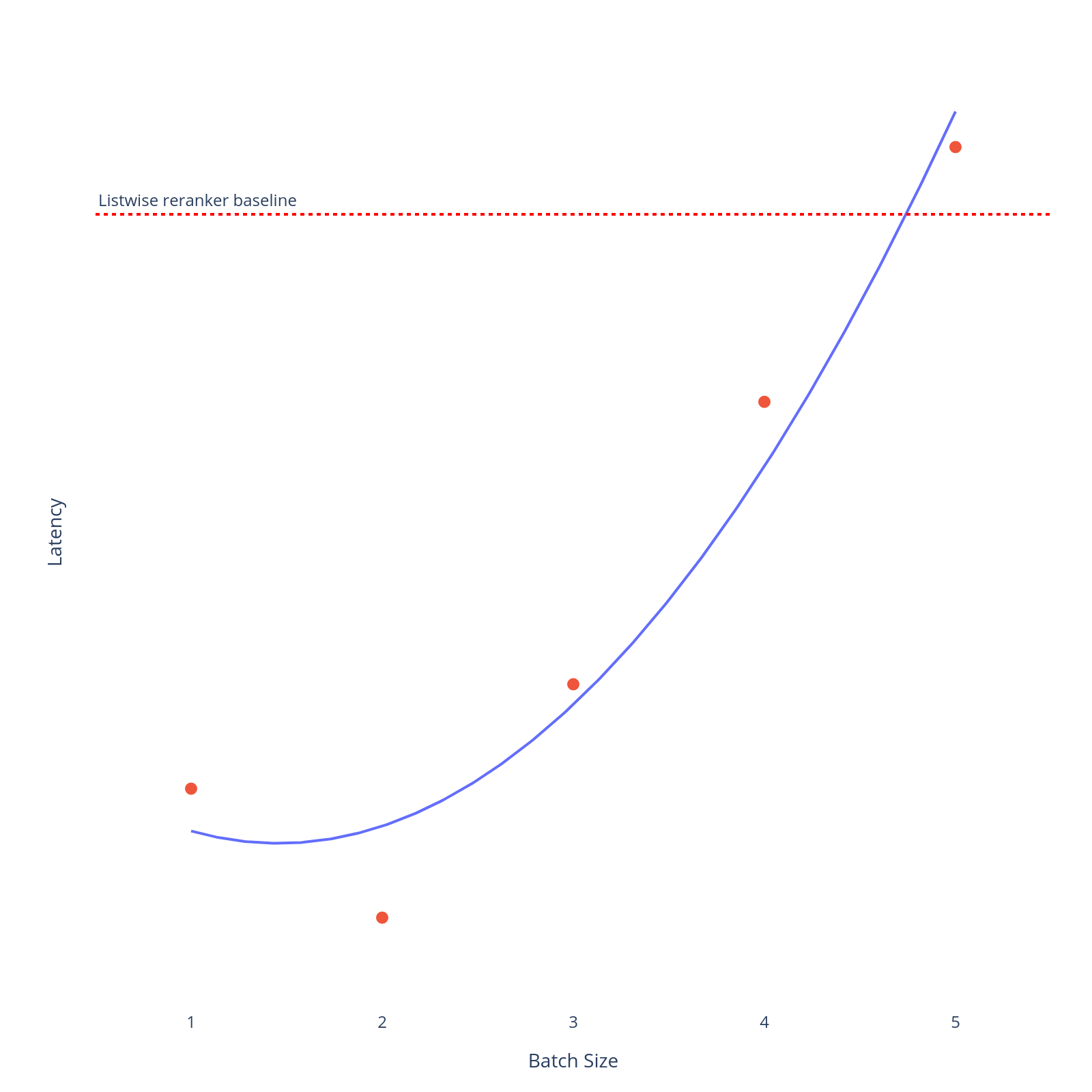
Your optimal batch size will depend on your model, hardware, and document length distribution, but the shape of the curve is likely to be similar. Latency improves quickly with small batches, then degrades gradually as sequences grow.
What’s next
Building low-latency AI agents requires more than fast models. It requires deep diving every layer of the pipeline and asking where the real bottlenecks are hiding. Reranking is just one of the many places for step wise improvements.
By moving to point-wise reranking and applying attention masking to batch document scoring efficiently, we drove down reranking latency substantially without overhauling the underlying model. The gains came not from brute-force optimization but from a well-placed structural insight: use of attention masking that preserved scoring quality while unlocking far more efficient computation.
At Decagon, this is how we think about building. The best performance wins are often not the most obvious ones. They come from pressure-testing assumptions at each layer and finding the places where a targeted change compounds into a meaningful product improvement. We will keep sharing what we find along the way.

Start improving your workflow with Decagon
With Decagon, CX teams don’t have to guess whether a change will improve CSAT or deflection. They can move quickly, measure what matters, and act on what works.
Join us
There are very few places where you can prototype with frontier LLMs, ship to production in days, and watch users engage with the systems you built—all while owning the entire stack, from intent parsing and tool usage to API integration and observability. This role at Decagon is one of those places.
From my own experience working across both agent development and broader engineering initiatives at Decagon, I’ve seen firsthand how uniquely impactful this work can be. Whether I’m building intelligent workflows for customers or designing infrastructure that supports our agent platform, it’s rare to find an environment where the work transitions from concept to production within days, actively powering user experiences and transforming how businesses operate.
If you’re looking for a role where you can:
- Build at the frontier of LLMs, automation, and user interaction
- Deploy AI agents that solve high-value business use cases across industries including retail, travel and hospitality, fintech, edtech, and more
- Work directly with customers on high-impact use cases
- Ship fast, iterate constantly, and own your work from idea to production
- Join a fast-moving, collaborative team solving real-world challenges with AI
We’d love to hear from you!
.png)



.svg)

.svg)

.svg)

.svg)

.svg)

.svg)

.svg)
The AI concierge for every customer.