Why off-policy training isn't enough: SFT, RL, and the limits of imitation
Posted on March 25, 2026


Article
Every business that deploys a customer-facing AI agent eventually faces the same question: what are my users actually asking about? Conversation categorization is the infrastructure that makes that answer reliable, driving routing, escalation, and product decisions.
The challenge is that category sets differ across businesses, evolve over time, and are defined in natural language the model has to reason over at inference time. This means static accuracy metrics alone are a dangerously incomplete picture of model health: the most costly failure modes are largely invisible to standard benchmarks unless you are explicitly looking for them.
We discovered this the hard way over the course of building a production classification system. The choice between off-policy and on-policy training shapes not just how well a model performs, but how it fails.
Frontier models are too large to deploy with production latency constraints, and small models aren't capable enough on their own [1], making knowledge distillation the default response: sample reasoning traces from a large teacher, train a small student, and iterate until held-out metrics converge. We find that deliberately sequencing distillation, on-policy training, and reinforcement learning (RL) yields a significantly more robust and accurate model — one that remains correctable through prompt updates rather than retraining as deployment contexts shift.
The classification challenge
.png)
Given a conversation history, the model must classify the user's intent and reason through its choice. Two structural properties make this setting particularly sensitive to the choice of training paradigm.
First, the model must produce a reasoning trace, not merely a label. Second, the correct answer is verifiable. Together, these create the setting where the choice of training paradigm has outsized consequences: the reasoning requirement means the model must do more than pattern-match, and verifiability is what ultimately enables us to move beyond teacher supervision to RL.
What SFT gives you — and what it costs
Supervised fine-tuning (SFT) via knowledge distillation transfers capability from a frontier teacher ensemble to a smaller student, enabling inference at a fraction of the teacher's cost [2].
This is empirically useful early in training — it provides wide distributional support and dense supervision on reasoning structure that sparser objectives cannot easily replicate.
But SFT has a structural limitation: the student always learns conditioned on the teacher's prior tokens, never its own, and this has concrete consequences in production.
Problem 1: Compounding errors at inference
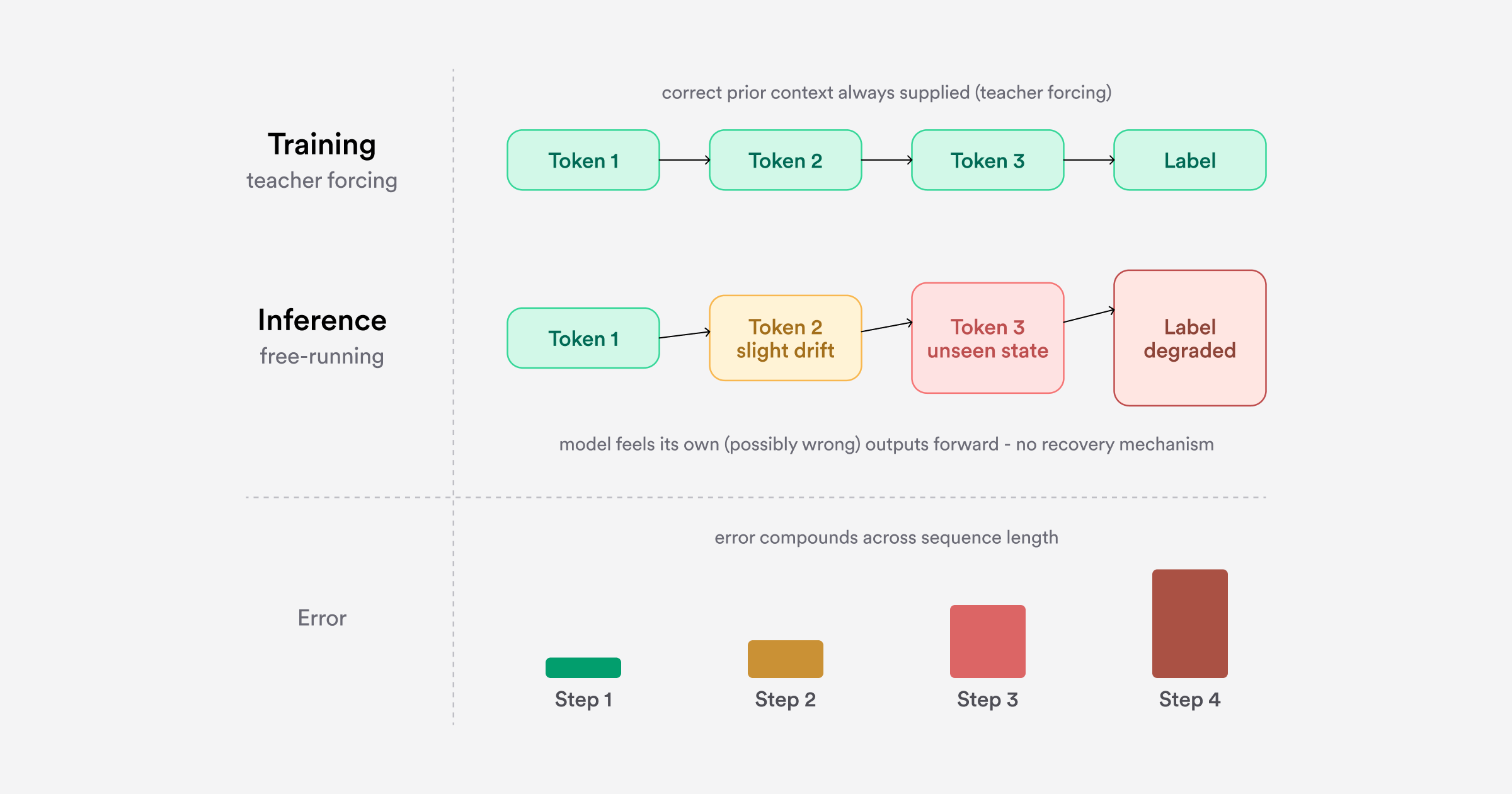
During training, the student always receives correct prior context via teacher forcing. At inference, it generates from its own previous outputs. If the model drifts early in its reasoning, it enters a state never encountered during training with no learned mechanism for recovery. Errors compound and the final classification degrades, a well-characterized problem in imitation learning, where compounding error scales quadratically with sequence length under naive behavioral cloning [3].
Data diversity mitigates this: varied conversation lengths, linguistic registers, and category distributions improve held-out performance. But when the category set is customer-specific and training data per customer is limited, the coverage diversity can provide is bounded. The mismatch remains structural.
Problem 2: Self-distillation doesn’t close the gap
One natural remedy is to close the distribution gap by having the student generate its own rationales. We provide the student with the correct answer as privileged information and ask it to produce a reasoning trace conditioned on that answer — a form of self-distillation grounded in the connection between distillation and learning with privileged information [4]. The student trains on its own token distribution rather than the teacher's, but conditioned on correct answers it won't have at inference time.
We tested this, but accuracy dropped relative to distilling from a frontier teacher model. Our leading hypothesis is that the intelligence gap dominates the style gap: high-quality reasoning from a superior teacher, even in a mismatched token distribution, is a better training signal than weaker reasoning expressed natively (though distributional noise in the self-generated rationales may also contribute).
Problem 3: SFT quietly erodes steerability
The subtler cost of SFT doesn't appear in accuracy metrics. The objective anchors the student to patterns in the teacher's training distribution — associations between specific input patterns and output trajectories rather than a general procedure for reasoning over criteria. When category definitions shift, as they routinely do in a multi-customer deployment, the model requires retraining rather than prompt-level correction. Standard benchmarks give no warning of this issue.
Steerability as a first-class metric
To make this failure mode quantifiable, we constructed a steerability benchmark by applying controlled perturbations to category descriptions on held-out examples: swapping definitional criteria between categories, reassigning boundary conditions, and generating synthetic categories with novel criteria.
For example, if Category A is defined by "the user requests a change to their subscription" and Category B by "the user asks about billing history," a perturbation swaps these criteria. A model reasoning genuinely from criteria should flip its predictions accordingly.
We measure steerability as the rank correlation between expected and observed label shifts under perturbation. Accuracy measures performance on the existing data distribution; steerability measures whether the model learned the task or its surface form. For a system where category definitions are business-specific and continuously evolving, steerability is the difference between a model correctable through prompt updates and one that requires retraining every time the deployment context shifts.
On-policy distillation: Better, but teacher-dependent
Before moving to RL, we explored on-policy distillation as an intermediate step that directly targets train-inference mismatch while retaining a dense supervisory signal.
Rather than training on static teacher traces, on-policy distillation generates supervision dynamically: the student produces its own reasoning rollouts, and the teacher scores or re-annotates them. The student learns to reason forward from its own prior outputs rather than the teacher's, directly closing the train-inference gap.
We found that on-policy distillation improved both accuracy and steerability over SFT. But it introduced a critical dependency: teacher quality at scoring student rollouts. When novel category schemas fall outside the teacher's confident reasoning — routine in our deployment setting — the student inherits those errors directly.
Reinforcement Learning: Generalizing beyond the teacher
Where on-policy distillation relies on a teacher to define correct reasoning, RL replaces that soft, potentially noisy supervision signal with a hard, verifiable one. The correct answer is checked programmatically — no oracle required.
The dependency doesn't disappear; it shifts from teacher quality to reward specification. But for tasks where correctness is verifiable, this is a categorically more reliable foundation. Recent work on reinforcement learning with verifiable rewards (RLVR) has demonstrated this principle at scale: DeepSeek-R1 showed that pure RL with binary correctness signals can incentivize sophisticated reasoning without any supervised fine-tuning data [6], using GRPO [7] — and its more recent sequence-level successors [8] — as efficient optimization frameworks for this setting.
On-policy exploration generalizes further than distillation can. Because the reward signal is grounded in verifiable correctness rather than teacher supervision, the model discovers reasoning strategies that work across the full input distribution, including novel category schemas and out-of-distribution conversations where the teacher's guidance would have been unreliable.
The result is a meaningfully more robust model that responds to lightweight correction rather than retraining as deployment contexts shift. The empirical effects are consistent: majority-class overselection drops, out-of-distribution generalization improves, and steerability is preserved. The model learns a general reasoning procedure over criteria — one not bounded by the teacher's competence on the task.
Putting it together: A training progression
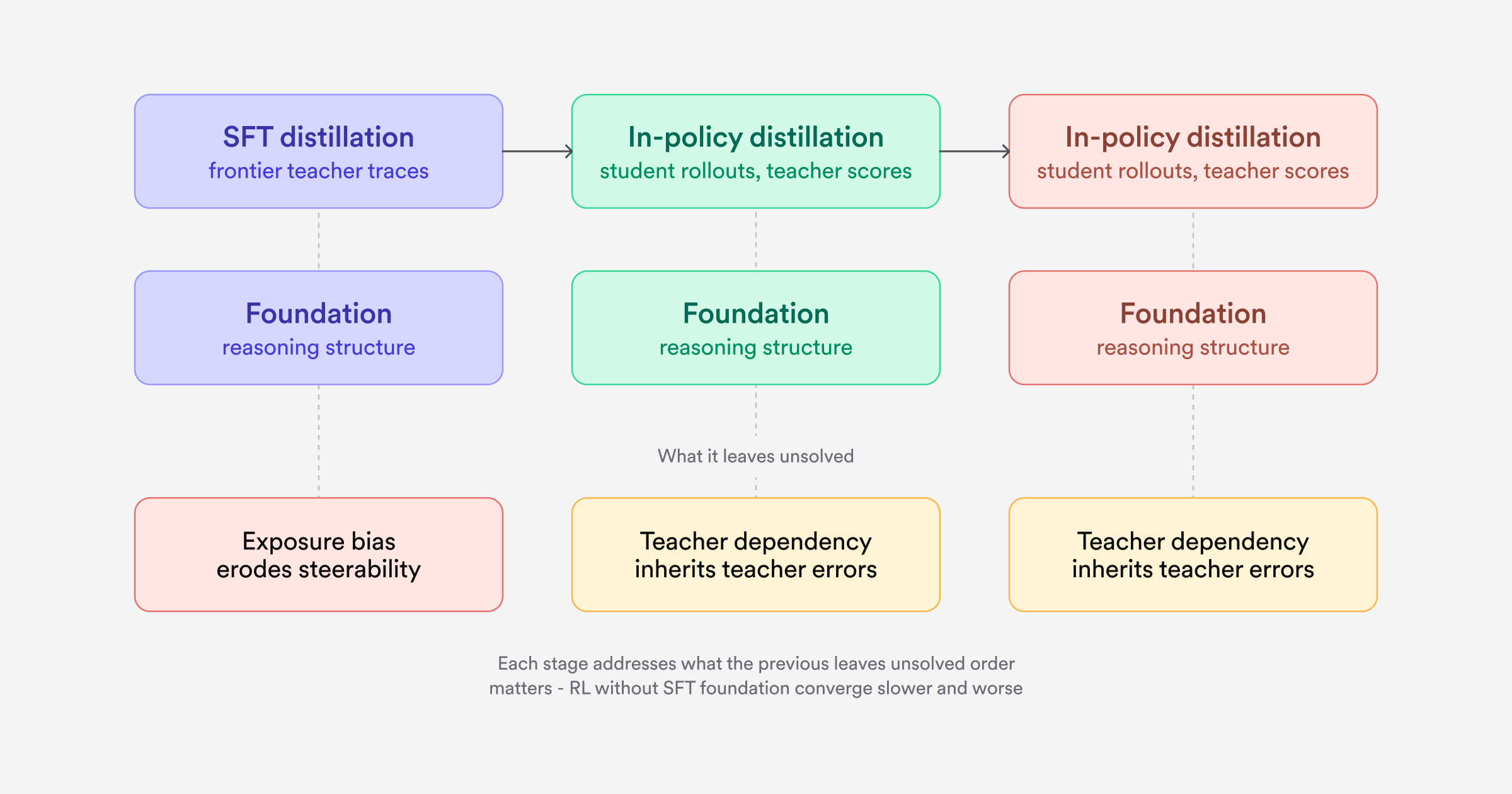
The ordering matters. In our experiments, RL applied directly to a base model without SFT initialization converged more slowly and to worse final performance — the dense supervision from SFT provides a critical foundation of reasoning structure that RL alone struggles to learn from scratch. This parallels the finding in DeepSeek-R1 [6], where cold-start SFT data before RL was necessary to address readability and stability issues observed in pure-RL training.
The three paradigms work best as a deliberate sequence, each addressing what the previous stage leaves unsolved: SFT builds the foundation, on-policy distillation closes the train-inference gap, and RL replaces teacher judgment with ground-truth reward.
The combined model is meaningfully more robust than any individual stage. Where the SFT-only model would consistently misclassify under shifted definitions and required retraining to fix, the full pipeline maintains accuracy more uniformly across categories and responds to targeted prompting and data augmentation. The practical difference is a model that remains correctable as deployment contexts evolve, rather than one that has to be retrained every time they do.
References
[1] Lu, M. (2025). Engineering Fast, Performant AI Agents Through Fine-Tuning. Decagon. https://decagon.ai/blog/fine-tuning-ai-agents
[2] Hinton, G., Vinyals, O., & Dean, J. (2015). Distilling the Knowledge in a Neural Network. arXiv:1503.02531.
[3] Ross, S., Gordon, G., & Bagnell, D. (2011). A Reduction of Imitation Learning and Structured Prediction to No-Regret Online Learning. AISTATS 2011.
[4] Penaloza, E., Vattikonda, D., Gontier, N., Lacoste, A., Charlin, L., & Caccia, M. (2026). Privileged Information Distillation for Language Models. arXiv:2602.04942.
[5] Agarwal, R., Vieillard, N., Zhou, Y., Stanczyk, P., Ramos, S., Geist, M., & Bachem, O. (2024). On-Policy Distillation of Language Models: Learning from Self-Generated Mistakes. ICLR 2024.
[6] Guo, D., et al. (2025). DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. arXiv:2501.12948.
[7] Shao, Z., et al. (2024). DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models. arXiv:2402.03300.
[8] Zheng, C., et al. (2025). Group Sequence Policy Optimization. arXiv:2507.18071.

Start improving your workflow with Decagon
With Decagon, CX teams don’t have to guess whether a change will improve CSAT or deflection. They can move quickly, measure what matters, and act on what works.
Join us
There are very few places where you can prototype with frontier LLMs, ship to production in days, and watch users engage with the systems you built—all while owning the entire stack, from intent parsing and tool usage to API integration and observability. This role at Decagon is one of those places.
From my own experience working across both agent development and broader engineering initiatives at Decagon, I’ve seen firsthand how uniquely impactful this work can be. Whether I’m building intelligent workflows for customers or designing infrastructure that supports our agent platform, it’s rare to find an environment where the work transitions from concept to production within days, actively powering user experiences and transforming how businesses operate.
If you’re looking for a role where you can:
- Build at the frontier of LLMs, automation, and user interaction
- Deploy AI agents that solve high-value business use cases across industries including retail, travel and hospitality, fintech, edtech, and more
- Work directly with customers on high-impact use cases
- Ship fast, iterate constantly, and own your work from idea to production
- Join a fast-moving, collaborative team solving real-world challenges with AI
We’d love to hear from you!
.png)



.svg)

.svg)

.svg)

.svg)

.svg)

.svg)

.svg)
The AI concierge for every customer.